
Disclaimer: This blog post was written by an external contributor about Google’s open source marketing mix modeling tool LightweightMMM. The approach laid out in this document is not reflective of how Recast approaches marketing mix modeling. The actual model specification can be found in the technical model specification.
After Apple’s iOS14 update and Facebook’s release of the Robyn Media Mix Modeling tool, everyone has been awaiting Google’s response. Because it uses aggregate data, MMM is a solution to the death of tracking and the cookie-less future, so it’s future-proof to any changes in the rules, whether they come from Apple or government legislation. Given the popularity of Robyn and that Google uses a Bayesian framework (closer to what we use at Recast), we thought it would be a good exercise to lay out exactly how google’s new tool works.
Just like our review of Robyn, this isn’t one of those “Us vs Competitor” posts: Google LightweightMMM is free, which makes it a better choice over Recast in many scenarios, much like Google Analytics is a better choice for most brands than a paid for tool like Amplitude or Mixpanel. However, where we do things differently, we won’t hold back on explaining why we do it that way. Because it’s open-source, anyone can look at the code and see exactly how LightweightMMM works. This transparency helps a lot when you’re dealing with a highly technical topic like marketing attribution, and we can all learn from Google’s contribution.
Most people won’t know this, but before Robyn, Google was actually way ahead of the game on MMM. In 2017-2018 they released several extremely useful papers on Bayesian MMM that inspired startups like HelloFresh when building their own custom models in-house. These papers were ahead of their time, pre-dating iOS14 and the industry’s scramble towards better attribution options. They provided a significant contribution to the industry, and taught me personally a lot about MMM, in particular Bayesian MMM, when I was still learning the field.
- Bayesian Methods for Media Mix Modeling with Carryover and Shape Effects. Jin, Y., Wang, Y., Sun, Y., Chan, D., & Koehler, J. (2017).
- Challenges and Opportunities in Media Mix Modeling. Chan, D., & Perry, M. (2017).
- Geo-level Bayesian Hierarchical Media Mix Modeling. Sun, Y., Wang, Y., Jin, Y., Chan, D., & Koehler, J. (2017).
- A Hierarchical Bayesian Approach to Improve Media Mix Models Using Category Data. Wang, Y., Jin, Y., Sun, Y., Chan, D., & Koehler, J. (2017)
- Bias Correction For Paid Search In Media Mix Modeling. Chen, A., Chan, D., Perry, M., Jin, Y., Sun, Y., Wang, Y. & Koehler, J. (2018)
If you notice a pattern that ties these papers together, it’s a focus on Bayesian methods and Geo-Level data to solve the myriad of problems that make MMM so hard. When I saw Google had released its own open-source MMM library, LightweightMMM, I was delighted to see it referenced the stellar work and thought leadership in the original Google papers. This is not an *official* Google product like Facebook’s Robyn is, and it’s not even the only Google MMM project – another engineer released Cookieless Regression Based Attribution, or ‘RBA’, in August 2021. However in my opinion this is the most comprehensive and useful response to Facebook’s entry to the MMM market that we’ve seen to date.
Marketing Mix Modeling in Python
Bayesian algorithms and Geo-Level support aren’t the only areas where Google has taken the opposite ideological approach to Facebook. This model is in Python, rather than R which Facebook chose for Robyn. Though the team at Facebook is working on a Python wrapper of their R library, the core development is likely to remain in R for some time. This is a big distinction not because one language is necessarily better than another (Recast uses R and stan internally), but because of accessibility, making it easier for you to build your own model. R has been the language of choice for traditional Econometricians and Statisticians who have been running MMM historically. However Python is a faster growing and far more widely used language, with 48% of respondents to Stack Overflow’s developer survey 2022 using it compared to just 5% using R.
How long does it take Google LightweightMMM to run?
A model with 5 media variables and 1 other variable (i.e. an organic variable) and 150 weeks worth of data, with 1500 draws and 2 chains, should take about 12 mins to estimate (on a normal computer). This is significantly faster than Robyn, which takes me around 2-3 hours for a similar size model. The difference in speed is down to a difference in approaches. In LightweightMMM, the Bayesian model estimates saturation curves and adstock rates natively as part of the model. They also use Numpyro with JAX for differentiation. This is a particularly ‘lightweight’ configuration which is where LightweightMMM gets its name. Whereas with Facebook Robyn there’s a multi-stage model where each component gets estimated separately: first,the Ridge regression model is run, then the hyperparameters are optimized by Nevergrad’s evolutionary algorithm for the next run. Google also isn’t using tools like Prophet to separately predict seasonality, though Prophet itself uses Bayesian techniques like what LightweightMMM is doing under the hood. It’s just handled natively as part of the model.
LightweightMMM optimizes the model based on accuracy alone as measured by MAPE – Mean Absolute Percentage Error, or how wrong the model is on the average day / week. This is less advanced than Robyn, which by default also optimizes Decomp.RSSD – a metric they invented that tells us how far away the model is from the current spend allocations. This was a controversial but important invention by the Facebook team, because it helps make the model more plausible, i.e. it won’t recommend really big changes in ad spend, or say that one small channel drove the majority of ROI. This is the hardest part of MMM, because if the model isn’t believable, no action will be taken. However Google does achieve the same aim through different means. Using a Bayesian framework, the priors that are set act as guard rails against unlikely results for marketing coefficients. In addition, Google’s media budget optimizer by default only recommends up to 20% changes in spend, though this is adjustable.
How long does it take to build a model with LightweightMMM?
Google’s project is less developed than Facebook’s, so there is no supporting documentation on MMM like there is on the Robyn site with their MMM guide.. Both projects accept the data in exactly the same way, so defining business scope, collecting and cleaning the data, presenting the results will take equally as long, approximately 8 to 14 weeks. If you’re undergoing a project to build an MMM using Robyn, it won’t take more than an additional day or so to run LightweightMMM as well, and compare the results.
Is it possible to get Google LightweightMMM running on a daily basis?
Because the LightweightMMM code is open-source, it’s completely legal to just take that code and run it on your own server. If you decide to self-host LightweightMMM, the server costs will be relatively negligible on AWS or Google Cloud, so really the main cost is the data engineering to get it set up. In talking to consultants who have helped clients set up similar infrastructure for Robyn, this tends to be in the ballpark of $5,000-$10,000 as a one off cost – primarily to set up the data pipelines to get the data all in one place for modeling.
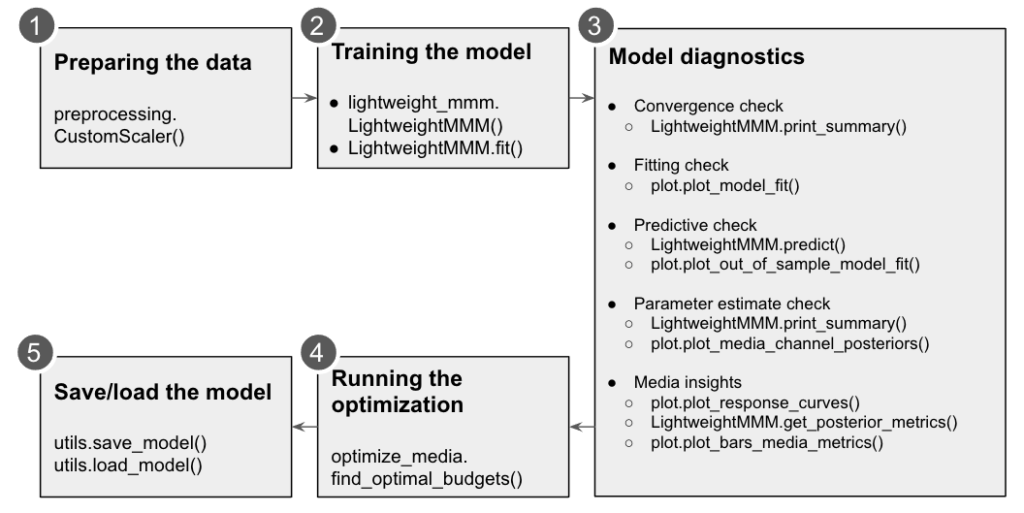
Different brands have different needs based on the state of their data, what systems it needs to be collected from and in what format, and how complex their marketing mix is. Making the build vs buy decision depends mainly on your in-house technical competency and the level of customization needed. This is the hardest part to be honest: it’s why Recast maintains a waitlist for new clients in order to handle all of this for them as standard. Like any software project you’ll need a developer on hand for updates and when anything goes wrong, and any changes you want to make to the base code or front-end data visualizations.
Outside of the technical hurdle to set LightweightMMM up to run daily (or weekly), the real issue is going to be dealing with dramatic parameter shifts when your model is run with new data. If you aren’t careful, you can go from saying that a campaign was super effective to super ineffective from one day to the next just because the underlying data changed slightly. Bayesian MMM using informative priors makes this less of an issue, and modifications to the LightweightMMM code (you can change the priors in the models.py file) can protect you from a lot of pain. However it’s something you want to have a smart analyst watching for. And of course, it’s easy to go too far in the wrong direction where you set your priors tightly to avoid a change in results, but then you miss a real change where a channel has actually gotten worse or better over time.
How does Google LightweightMMM estimate the adstocks and diminishing returns of advertising?
There are three main models available with respect to media spend. The standard is “adstock” which applies an infinite lag that decreases its weight as time passes. This accounts for the lagged effect of ad spend on sales, for example many people might buy a week or so after seeing a TV ad, rather than on the day. This default does not include saturation effects however, which handle the reality that as you increase ad spend, performance tends to decline i.e. you can’t double your spend and expect sales to double also. For this you need to use the “hill_adstock”, which adds additional parameters to estimate and account for that. If you’re a relatively smaller business spending less than $100k per month on ads it’s unlikely you’ll see a significant saturation effect, so it’d be fine to use the default. The carryover model is simply a different way to model adstocks, and has gotten me better results anecdotally than the default.

This is an area where Facebook is currently way ahead. They not only offer more adstock and saturation model options, but they spend the majority of their compute on figuring these out. The reason Robyn runs for so much longer is because they build 10,000 models with Nevergrad’s evolutionary algorithm in order to estimate the parameters for adstocks and saturation. There has simply been more focus put into this part of the model, at least so far. That said, Google’s approach is definitely passable here, so this is more a technical note for advanced teams.
How does Google LightweightMMM account for seasonality?
LightweightMMM accounts for seasonality natively in the model, with a sinusoidal parameter with a repeating pattern. There’s also an Intercept (a baseline variable) which is standard practice, as well as trend and error terms. This is not so different from what Facebook does, where they use a Bayesian open-source library called Prophet, that automatically separates out the annual seasons from the general underlying trend, and adds holidays and other events based on the country the model is being built for. These are included as variables in the model to control for seasonality. This is a standard approach that we happen to think is completely wrong: controlling for seasonality means assuming your marketing performance doesn’t change in periods of peak demand! Blindly following a model like this can lead to the wrong conclusions, like under-spending during key holidays like Black Friday.

Is it possible to calibrate Google LightweightMMM with our domain knowledge?
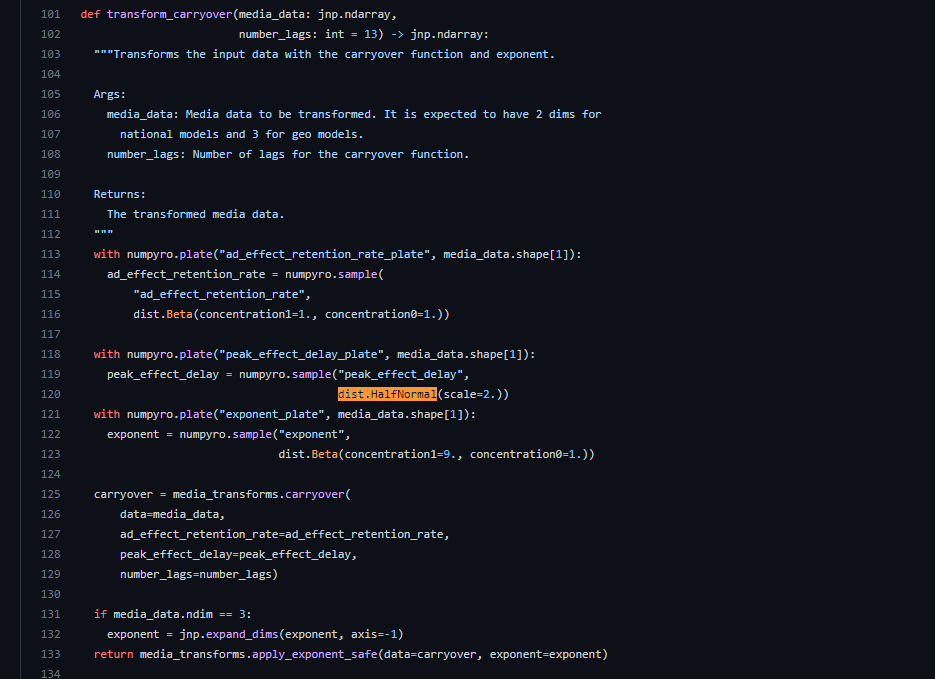
Out of the box the library doesn’t have specific features for incorporating domain knowledge, unlike Robyn which has this as a specific feature and optimization target for Nevergrad’s evolutionary algorithm. However this is something that natively works well within Bayesian frameworks, as you can use the priors of each parameter to inform the model of strong or weakly held opinions you have about the nature of how each channel will perform. The way that LightweightMMM is built does allow for a smart data scientist who knows what they’re doing to modify the models.py file and use their own priors (search for “dist.HalfNormal” in the models.py file for an example of how priors are set in the codebase), though it’s recommended for all but advanced users to simply use the defaults.
At Recast, We use an algorithm called Bayesian Markov Chain Monte-Carlo, just like LightweightMMM uses. However we’ve built more flexibility into our model in terms of what data and business knowledge we incorporate to arrive at the correct model. It can be as simple as defining that marketing spend can never drive negative sales, or as complex as incorporating your other attribution methods into the model as priors, so that the resulting model is consistent with what you know and you get a single source of truth you can rely on.
Can we use LightweightMMM to understand recent performance?
This is a common question from clients of traditional marketing mix modeling, which assumes that marketing channels perform the same across all time periods (accounting for saturation). Of course this might not be the best assumption to make: unlike TV, Print or Billboard campaigns which run once or twice a year, digital channels are always on and always improving with optimization and creative testing. Therefore it might make sense to look at a more recent modeling window, but then you run into another problem: not enough data! If you have less than 2 years of data it’s hard to establish seasonality, and if you have less than 10 observations (days or weeks depending on your model) per variable in the model, you risk overfitting the data, making the model unreliable.
This is something Recast covers by allowing the model coefficients to update for each time period, using the previous period as the prior (today is likely to be similar to yesterday). This means marketing performance can go up or down over time and still maintain model stability and predictive power. Unfortunately as of yet, LightweightMMM doesn’t offer the same functionality. Facebook’s solution is to offer a modeling window, which lets you take the full length of the data to determine seasonality, but then zoom into a window you set, for example the last 3 or 6 months, in order to build the model. You can also refresh an already built model with new data, with their model refresh function, which is often used by teams who put Robyn into production to run every day. However, the shifting modeling window can be problematic for channels that have really long adstocks or shift effects (not uncommon at all in our experience) and can lead to dramatic parameter shifts as the modeling window moves around.
What recommendations can LightweightMMM give me to help with decision making?
LightweightMMM has some of the standard output you’d expect from an MMM, but it’s missing a few pieces. For example there’s no waterfall chart of contribution by channel, or share of effect versus share of spend, both of which are standard in Robyn (and Recast!). There are mainstays of MMM such as accuracy vs predicted, and they go the extra mile here and provide both in-sample (data we fed to the model to train it) and out-of sample (data the model hasn’t seen yet) charts and accuracy metrics, which helps quickly diagnose how reliable the model is.
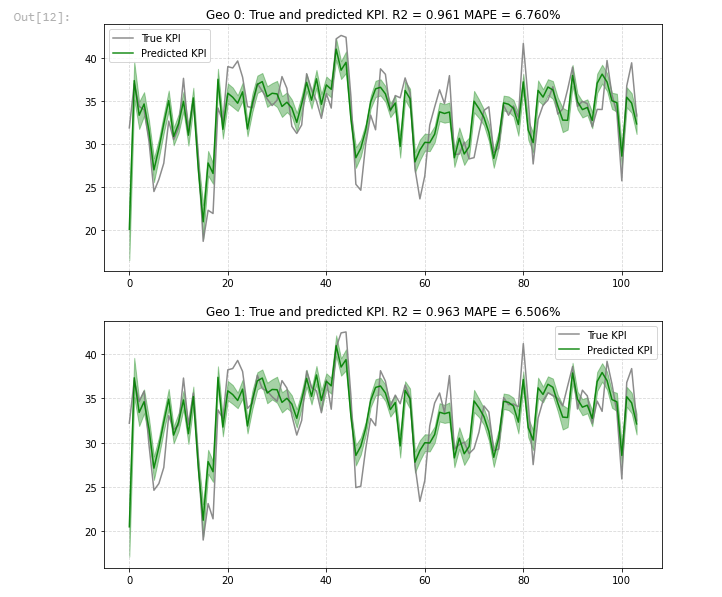
The interesting thing about LightweightMMM’s output is that it natively supports geo regions. So for example if you pass it multiple geographic regions it outputs charts for each one, as well as rolling up overall accuracy and performance metrics. This is something that can be incredibly time intensive to do yourself, so is a big benefit and unique to LightweightMMM. Geo-level data in my experience has led to huge increases in plausibility and accuracy in the model, because it results in more observations and variance in the training data, so this is a killer feature for LightweightMMM. The other thing it does well is response curves: there is good detail as to where each channel starts to get saturated, which is a big strategic advantage. Of course Robyn also has response curves, but I find the actual media optimizer for LightweightMMM more intuitive to use, with less radical results.
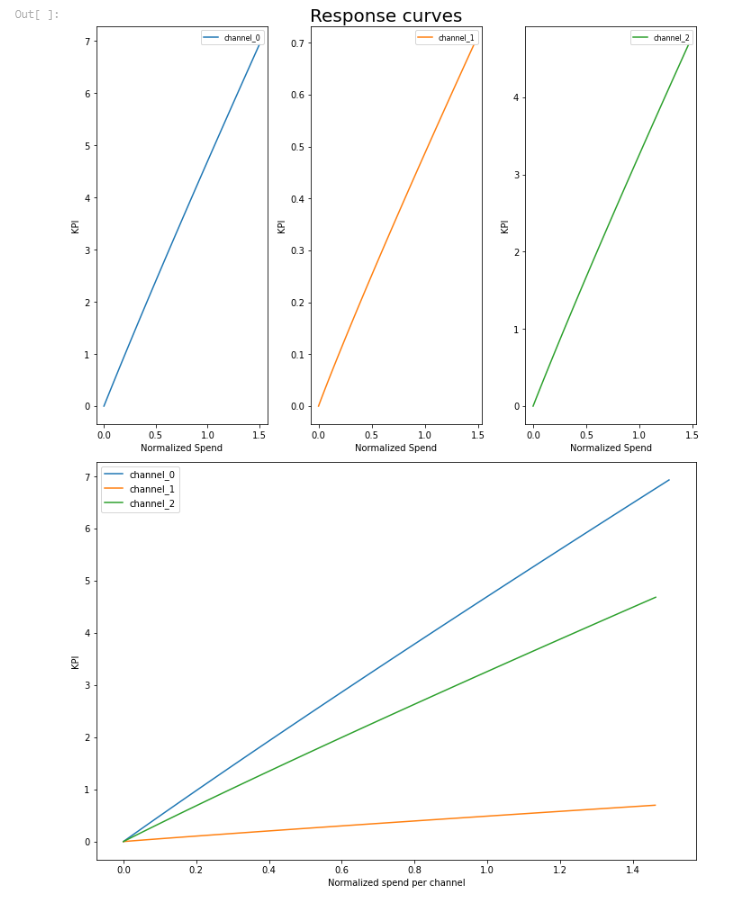
All of this is fairly standard with any MMM vendor (even the ones that do it in Excel), though they are missing a few key outputs, and Robyn’s clean and actionable one-pager puts them to shame. In Recast we have these various components available in a dashboard, for our clients to look at, updated daily. Of course it is possible to put LightweightMMM in production and build your own dashboard. As their code is open source this can be a good solution if you have extra data science and engineering resources, and can consult with an Econometrician to interpret the results.


