At Recast we believe that in order for our customers to get value out of Recast, the model needs to be correct. That is, it needs to give valid, actionable inferences that our customers can use to drive bottom-line improvements in their business.
In order to get to a correct model, we have a white-glove model configuration and onboarding process in which our data science team works hand-in-hand with our customers to configure Recast’s state-of-the-art marketing econometrics engine for the particular needs of our customer’s business.
Sometimes the terminology of “configuring” the model is confusing to customers who are used to working with consultants that promise them a “custom model build”. The truth is that Recast’s model is much more customized than most consultants’ models.
Factors like the time-shift between when spend takes place and when revenue is realized are estimated from the ground up by the model for every client (actually, not only for every client, but for every marketing channel, and for every dependent variable we model); they are not simply chosen by an analyst based on what they’ve done on the past — or what makes the model “look right”. The reason we use the term “configuration” (and not customization) is that the model — data-driven machine learning and statistical algorithm — achieves these highly specific results for us with a small number of input parameters along with the marketing data provided by the customer. It is these input parameters that we need to choose along with the client.
Here is how the configuration and model validation process works at Recast.
Deep-Dive Business Review
First, we need to understand our customer’s business and all of the unique aspects of their marketing program. Our data science team has a rigorous set of questions we will work through with our customers marketing and analytics teams to understand things like:
- What are the main drivers of business and marketing performance?
- Have there been any major changes to how channels have been managed historically? New agencies brought on?
- How does branded search work for your business?
- Are there any “affiliate” marketing channels? How are those deals structured?
- How do you structure pricing promotions?
- How do new product launches impact your business?
- Etc.
We recognize that most marketers we work with aren’t statisticians. That’s okay! This process is designed to help our team of data scientists correctly specify the statistical model given all of the complexities involved in doing marketing science and econometrics.
Once we have all of these questions answered, we can start with an initial model configuration that we use for validation.
Parameter Recovery
Parameter recovery is the first step in the model building process. Once we have an initial configuration, we want to answer the following question:
If we know the true correct answer, can the model as it is currently configured identify that answer and give it back to us?
That is, we take the initial configuration and randomly choose a set of parameters. This might be something like:
- Facebook has an ROI of 4.5x this month and 2.5x last month, and the time shift is 23 days
- Linear TV has an roi of 3.2x this month and 4.5x last month and the time shift is 12 days
- Etc.
Then, we assume those numbers are true and generate a KPI column (often revenue or new customers) using that set of parameters. We then run the model-fitting process like we normally would, and we confirm that the results of the model give us back the answers that we set initially.
This tells us that as long as our model’s assumptions line up with how marketing works in the real world, we know that we have the ability to capture the true answer.
Model Stability and Robustness
Next, we want to confirm that the results are not sensitive to small changes in data. This is a huge problem for a lot of marketing mix models: the analyst will run the model on slightly different data and the results will change dramatically. This is a sign that the model isn’t robust and generally is an indicator of a poorly specified model.
In order to check stability and robustness, we will run the model 6 different times going back for the last six weeks. We run the model as if we were running the model 7, 14, 21, 28, 35, and 42 days ago. So we chop off the last N days of data, and run the model as if we were back in time.
Once we have the results of all of these model runs, we review the results for stability and robustness. We want to be sure that the model’s parameters don’t “jump around” as the model sees slightly different sets of data.
If the model’s results are stable over time, we can feel confident that we have a robust model specification that won’t cause whiplash with our customers into the future.
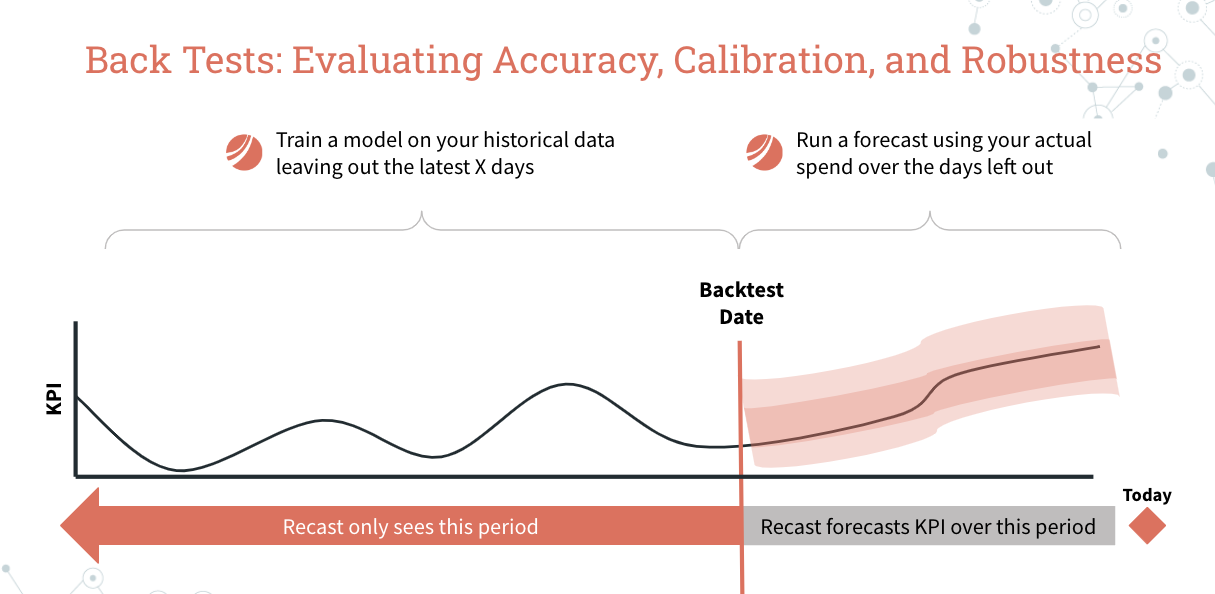
Back-testing and hold-out predictions
Once the model passes all of those other checks, we want to make sure that the model can consistently predict the future. That is, we want to validate that the model can predict the KPI being modeled into the future on data the model has never seen before.
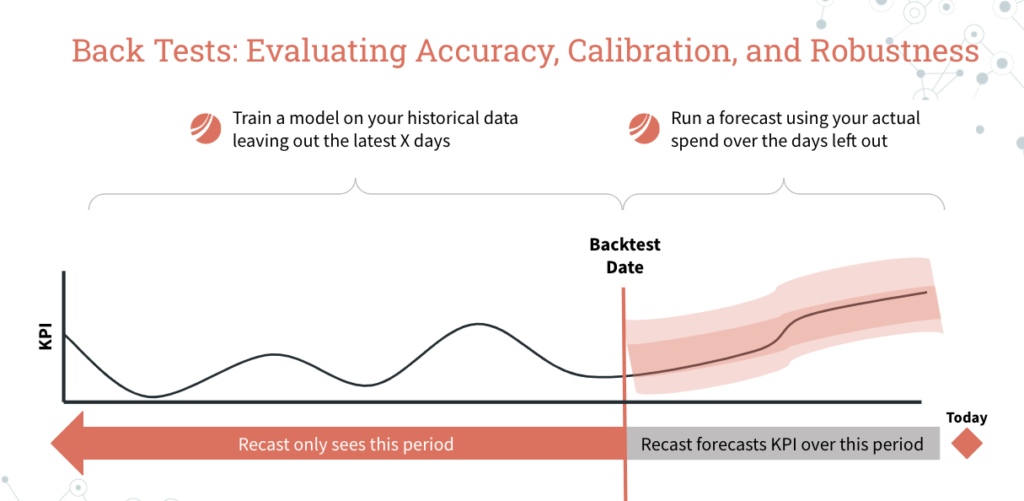
The idea is that we will do something similar to the robustness checks above, except this time we are going to run a forecast “as of” 30, 60, 90, 120, 150, and 180 days ago. So we will fit the model, and then use the actual spend to make a forecast over a time period that the model has never seen before.
It’s important to note that we try to make this forecasting exercise as realistic (and difficult) as possible. It would be cheating to use predictors like web sessions or branded search spend since those variables are really “outputs” of the marketing program and contain too much information about the very thing we are trying to forecast — the effectiveness of each channel’s marketing spend — to use in a genuine forecasting exercise.
If the predictions from the forecast consistently line up with the actual KPI, then we know that the model is capturing true underlying signal and we can be confident in our forecasts going forward.
Conclusion
Our model configuration process is extremely robust and thorough. It is generally much more robust than the process used by data science / econometrics “consultants” that tout the benefits of their hand-tuned models.
Because Recast uses the power of software and machine learning to automate these processes we are able to build better models with more predictive accuracy in a fraction of the time and cost.


