Marketing Mix Modeling (MMM) is hard. The core difficulty is that MMM is trying to solve a causal inference problem where there is no ground truth to compare the model results with. There is no ground truth source that can tell us what the true incrementality of TV is as an advertising channel.
That means that the core problem of MMM is not running a model and simply getting results, the core challenge is actually validating that those results are correct. It’s trivially easy to construct a ton of different MMM models which have similar accuracy performance but can be difficult to choose between them. Open source tools like Facebook’s Robyn generate a series of “candidate models” that often yield totally incompatible results. One model says TV is a great channel and the other says TV is awful but according to the fit statistics, the models are equivalent.
At Recast, we take model validation very seriously and we talk a lot about validating a model through testing. The idea is that we don’t want Recast to just yield “interesting insights” but rather we want to use Recast to drive actual budget changes and efficiency improvements. And it turns out that we can actually use those budget changes to test and validate the models results, leading to a virtuous cycle of better marketing performance and better model performance.
There are three different ways we think about validating Recast through testing:
- Backtesting and holdout forecast accuracy
- Randomized control trials / geo-lift tests
- “Go dark” and “spend up” tests.
We’ll cover each of these in slightly more detail below.
Back testing and holdout forecast accuracy
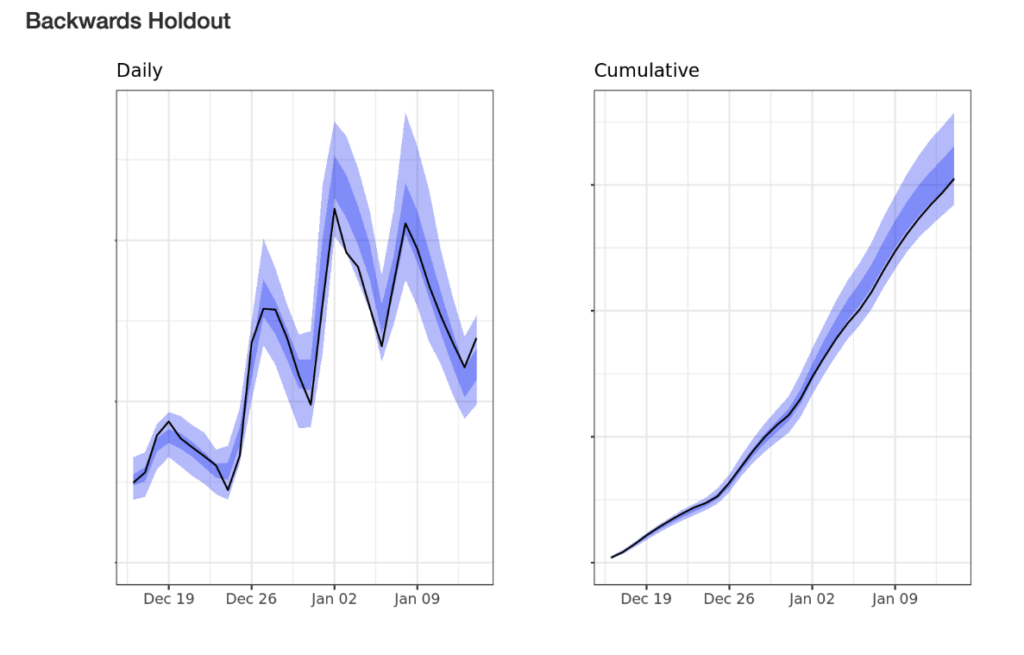
Basically the idea is that we can use a model only trained on data up to 30 (or 60, 90, etc) days ago and then use that model to make a prediction about what will happen given the actual marketing spend observed during that period. For example, recently one customer of ours pulled back dramatically on their facebooks spend over a two week period and were very comforted to see that their Recast model from last month correctly predicted their total business performance during the weeks of the pull-back.
This is similar to the idea of “cross-validation” but it’s a little bit different than the way cross-validation is implemented for most machine learning use-cases. Since MMM is a time-series problem we have to be more thoughtful about validation and so we use holdout forecast accuracy instead of just simple cross-validation.
Randomized control trials and geo-lift tests
If Recast identifies a channel that seems to be a strong or weak performer but that conflicts with last-tough or platform reporting, we can run an explicit lift test to validate. We might do a “ghost bidding” test where we serve PSA ads to some segment of the audience or do a traditional geo holdout test.
Recast can be a great tool for deciding what the highest priority lift-tests should be.
“Go dark” and “spend up” tests
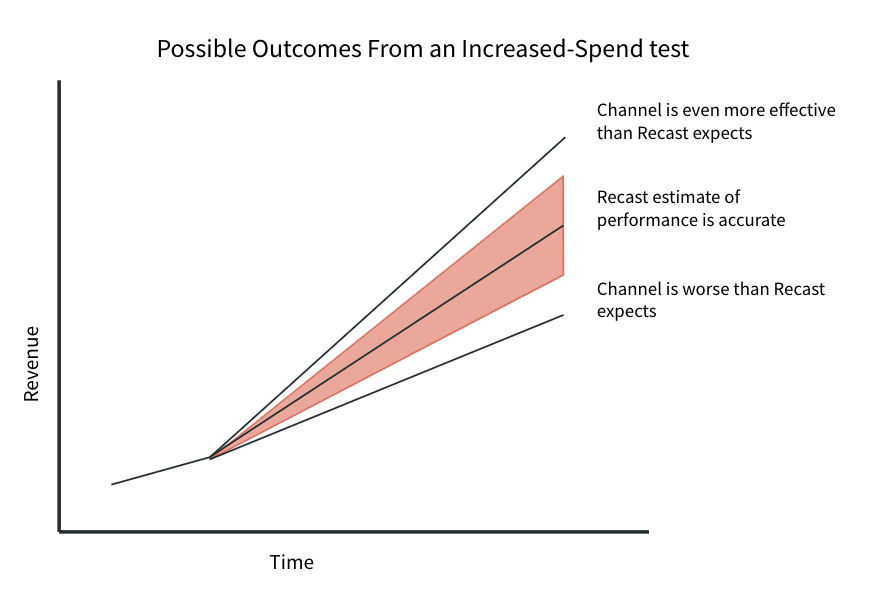
We can recommend turning off (or doubling, or whatever) spend in a certain channel and then validate that top line results move in a way that is consistent with Recast’s forecasts. Recently we recommended that a customer turn off spend in a channel that made up 7% of their paid marketing program and we saw that their total revenue declined <1%, which was exactly in line with Recast’s forecasts and estimates of channel performance.
Conclusion
Unlike other MMM platforms, Recast is actually designed to be used. Recast works best when customers use the model to drive budget changes which can then actually improve the model’s results over time.


